Web端防的一些些
- WebSiteSecurity
有备而来,但就像堂吉诃德撞向风车。
说起 Web 安全绝大多数人第一反应便是渗透、漏洞,这种以夺得目标服务器的为目的的攻击方式我在这里定义为传统安全。从方式上来说,这种攻击的点主要是业务代码的缺陷,无论是自身代码本身的脆弱性还是使用了不安全的框架、不安全的加密算法等,实际上都是防守方本身的产品的缺陷。那么这里聊的则是另一个维度的安全问题,可能一般叫 端防 或者说 API 安全。没有错误的服务不代表是安全的服务。听起来有点诡异,一个没有问题的代码怎么会不安全呢?对于企业来说,提供服务给正常用户是理所当然的,然而放服务被大量恶意利用的时候就会出现安全隐患,对企业本身的利润造成危害。一个直接就能看到的例子就是:12306 抢票、京东脚本秒杀,攻击者并不直接攻击服务器,而是对某个 API / 服务 进行非预期使用来牟取利润。
爬虫
正常人对爬虫的印象往往是爬取数据,而实际上爬虫更多的利润在于通过批量的自动化操作来模拟正常人类的行为从而达到某种目的来产生收益。对于美团、饿了么这类生活垂直类的平台,一个敏感的点就是 商家评分 ,高评分的商家往往会得到更多用户的青睐,于是一个需求就出现了:商家需要更高额的评分。想要通过人为的刷分那么实际上 成本/收益 划不来,于是提供这个服务的人往往采用自动化工具的方式来实现行为,更进一步的就是逆向协议。概括来看,后者的成本主要是技术成本,而前者的成本则是需要基础的投入。对于企业来说,这类人群被定义为黑产。
那么更进一步的介绍一下目前黑产主要的分布:
- 羊毛党:利用群控、批量自动化来大量薅取企业福利活动 (比如 抖音极速版 开红包)
- 刷分类:从商家的需求来赚取利益,影响企业的信誉、影响正常消费者
- 引流:商企合作并不奇怪,但工作室可以更低廉的价格来将这部分利润赚走
- 爬数据
- …
有人的地方就有江湖,有利益的地方一定会有商人。黑产并不是简单的、具体的某个人,而是一个有规模的产业链。其中有上游的生产资料提供商,技术提供者,也有中间的销售,以及最终的工作室。下面则是整个链路的概略图,其中每个环节的人都有可能承担多个角色。
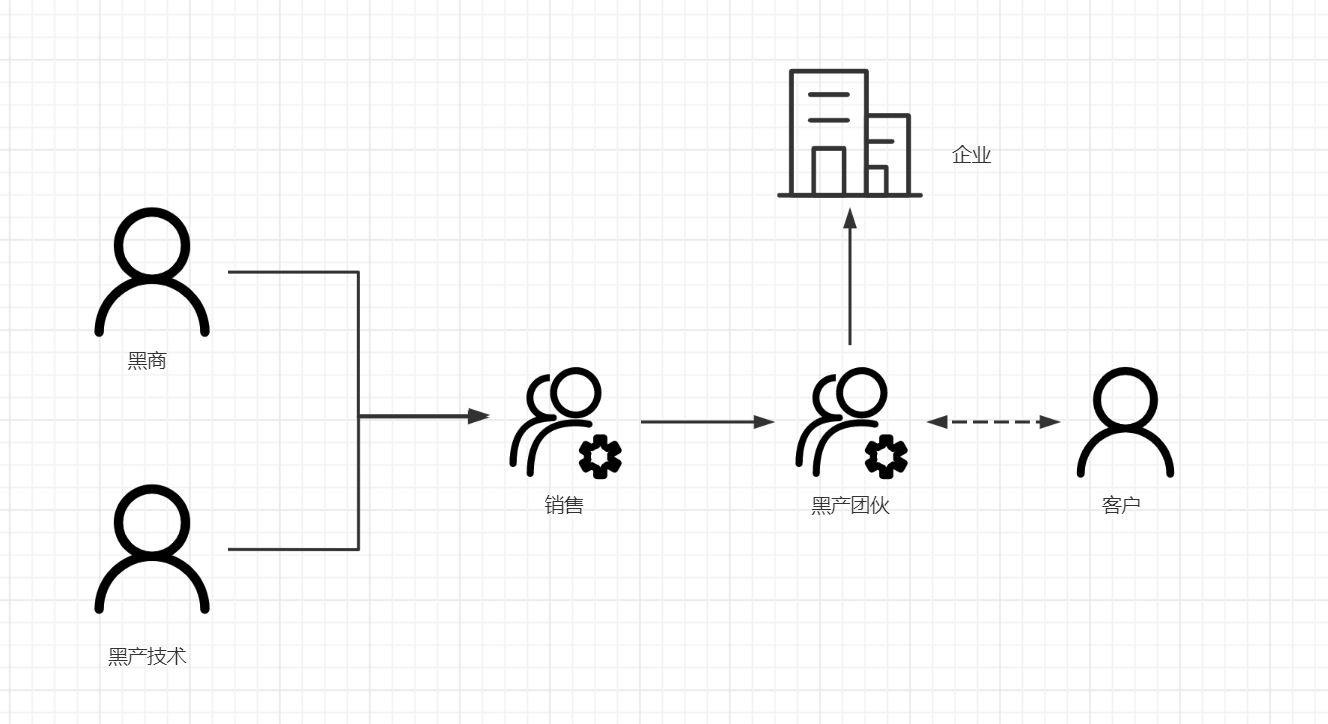
黑产技术
不谈手法,就无法理解这个链路。前文已经提到黑产主要使用 自动化工具 / 协议破解 两种方式来进行批量操作,那么我们接下来分别来看具体的技术手段。
自动化工具
自动化工具指的是利用脚本来模拟正常人的行为和客户端进行交互。在 Web 端常见的自动化工具有 Selenium , Puppeteer ,Playwright,这几种工具利用Webdriver 和浏览器进行交互,还有一种 Automa 这种门槛相对低的录制类操作。在 App 端常见的工具有 Appium 和 AutoJs ,他们同样是模拟了正常人类的一些行为。
由于自动化工具利用的真实的客户端,所以它的门槛相对低,只要浅浅的学习就可以达到目的,一般初学者只要花费一两天的时间就可以达到不错的效果。那么与之相对低的,因为使用了真实的客户端,它的成本就会提升,需要更多的机器资源,想要达到一个定规模需要更高的初始投入。
自动化工具除了成本,还存在其他缺陷,目前看来主流的自动化工具或多或少会向客户端注入一些特征从而可以反制。最基本的便是 window.navigator.webdriver 这个属性,没有自动化工具介入的浏览器并不存在这个值。从特征出发的防护,我们一般称为环境检测,这种思想实际上和传统的 Windows 对抗下的调试与反调试类似,通过查询一些变量来窥探是否为 异常客户端。然而基于环境的检测,往往会被环境绕过。市面上存在许多隐藏特征的方案,比如 stealth,undeteced_webdriver 这样的插件,这又与 ScallyHide 这样的插件不谋而合,那么进一步的又可以通过针对插件本身的特征来进行检查。
就如同世界没有两片相同的雪花,每台机器的也不尽相似,尽管他们是同样的产品,最终依然会有细微的差异。浏览器指纹就是这么一种技术方案,通过显卡、声卡的表现来对客户端进行描绘,生成一个类似身份证的指纹信息,通过风控算法来进行区分正常用户和异常用户的区别。针对指纹的绕过同样也有技术方案,归根到底这没有摆脱环境检测,攻击方和防守方都只能通过一个沙盒来获取信息,那么攻击方自然可以通过修改环境本身来进行绕过,常见的方式有 Hook 函数的返回值、自编译浏览器。
那么更进一步的防御则完全绕过了传统的环境检测方案,而是针对具体的用户行为来进行区分。自动化工具无法避免的一个问题就是 目的性强、行为操作固定,由此产生针对行为序列的分析,由风控来查杀自动化工具,这种方式存在误杀,但这是一种通杀的方案,基本所有的企业都会采用这种方案,并且提供了救活的机制,比如抖音会下发验证来判断是否为正常用户,以及 DNF 同样会弹窗确定是否为自动脚本。想要对抗这种强有力的防御一般也只有破解验证来获取白名单从而误导风控,不过缘由此生,也因此灭,破解的同时亦有可能被风控检测,对抗是时刻存在的。
协议攻击
自动化工具并不需要利用者有高超的技术手段,协议破解则不然。客户端是如何和服务器进行交互的?答案是通过各式各样的请求,用户的正常请求往往是通过和客户端上的组件进行交互,由客户端发送请求和服务器进行交流,那么黑产想做的就是跳过客户端交互的行为直接和服务器进行交互。在很早以前就有抓封包这种游戏作弊的手段,这里同样也是。
常用的抓包工具有Fiddler,WireShark,浏览器的网络功能等,通过对请求的分析来确定那些参数是需要提供的。在早期,人们对这件事的注意并不多,所以可以轻轻松松的利用接口。而现在,往往会在请求内容中附加加密参数来防止被接口被大范围的恶意利用。在论坛上常常见到的就是 XXSign 算法破解实际上就是在破解这些加密参数,加密参数基本上是利用请求体的内容来生成一个参数来确保数据的一致性,这个生成的过程将有客户端代码提供,那么构造协议的成本就会被转嫁到破解客户端上,只要将客户端代码逆向就可以得到构造协议的逻辑。客户端加固早在很多年前就有了成熟的方案,针对可执行程序的有 VMP ,Themida 这类加壳工具,以及 Ollvm 这种在编译期对生成代码尽心混淆的思路。在浏览器端同样有 JsVMP ,JsObf,Proguard 这种工具,那么协议逆向的成本随着代码保护的强度提升而快速提升。以上的破解思路一般被称为 白盒 ,除此之外仍然有一种黑盒调用的方式,将全部算法扣取出来人为调用,从而达到目的。白盒的成本远大于黑盒调用,但黑盒调用主动权实际上并不完全在攻击方,遇到更强的防护时黑盒调用存在诸多问题,容易被反制,不过很多企业做不到这一步。一种二者结合的方式是 Rpc 调用,通过让宿主机来调用目标函数从而避免传统黑盒调用的问题,将结果用户构造协议,从而避免白盒代码的成本。这种方式抗防御的强度更高,不过也引入了额外的成本以及问题,宿主机的存在影响了效率,以及加大了被发现的风险。
黑商
在上文提及了对抗,当黑产被发现时,服务端则会对黑产采取一定措施,常见的方式有:封禁账号、封禁 IP。对于黑产来说,账号、IP 都是不可避免的成本,没有天衣无缝的攻击,总会落下一点马脚。攻防的本质是成本的攻防,当无利可图时黑产自然褪去。防御方既然要尽可能的提高成本,那当然包括资源的成本。常见的物料提供有:黑手机号、接码平台、隧道IP提供商、秒拨平台、号贩子等,针对黑商的防御实际上是从源头来进行防御。然而想要做好这件事并不容易,之所以做黑商而并不选择做黑产就是打算规避风险,通过比特币这种交易方式几乎不可能溯源交易(即便溯源了很多时候也不能怎么样,卖账号违法不到哪去)。目前看下来,主要的防御集中收集大量的信息来进行对抗,毕竟资源始终还是有限的,只要覆盖的够多,那么成本就会相应提高,作恶成本自然上升。至于如何收集那就是一门学问了,黑的白的都有,能抓到耗子的就是好猫。这一块是一个相对无解的问题,嗯,是这样的。针对封禁 IP 还存在一些一键式的解决方案来进行规避,服务商提供一个 CloudAPI 来代理爬虫流量,比如 Zenrows。
黑产客户
如果只把视角停留在攻击那就无法挽回损失,除了直接造成利润的羊毛党无法补救,剩下的还是有回捞的机会。一个默默无闻的正常用户不会一瞬间增加成百上千的点赞,那么往往是和事件绑定的。通过对用户画像的分析可以在一定程度上识别异常用户,从而反向推出黑产团伙使用了哪些账号、IP ,采取一些措施,会让黑产以及黑产客户双方造成损失。
通过社工的方式同样是个不错的选择,通过和黑产打交道来获取一线信息从而进行防御来的非常直接。类似的思路还有扮演黑商、IP 代理商的来钓鱼,其实就是蜜罐的做法。
总结
在有限的人生里做更多的事情!别做黑产。